

These practices are based on my personal experiences and opinions. I am always open to better suggestions and would love to hear your thoughts for improvement!
Folder Structure
A well-organized Go project should follow a structured layout:
More detailed: https://github.com/golang-standards/project-layout
📂 project-root/
├── 📂 cmd/ # Main applications for the project
│ ├── 📂 app/
| | └── 📄 main.go
│ ...
├── 📂 internal/ # Private application
| ├── 📂 <aggregate-root-1>/
| | |── 📄 usecase.go
| | └── ...
| ├── 📂 <aggregate-root-2>/
| | |── 📄 usecase.go
| | └── ...
| ...
├── 📂 pkg/ # Library code that can be used
├── 📂 configs/ # Configuration files and templates
├── 📂 scripts/ # Utility scripts (build, deploy, etc.)
├── 📂 test/ # Additional test data and mocks
├── 📂 container/ # Managing object lifecycle(optional)
├── 📄 README.md # Project documentation
├── 📄 go.mod # Module definition
/pkg
This folder should not contain any business logic and should not access the internal package. It is meant to include packages that handle integrations with third-party libraries that the internal package can use.
At any point, the packages within this folder should be transferable to another project without modification.
/internal
This is where all business logic resides. We should aim to follow Domain-Driven Design (DDD) principles as much as possible. We should avoid using generic utility or helper packages.
Each aggregate root should have its own package, containing only the code relevant to that aggregate. The usecase.go
file within each package handles the application flow, acting as the entry point for domain logic execution.
/container
This folder is used to manage object lifecycles using samber/do. All required structs should be defined and registered here. No package should access the container package directly. Instead, the container should be accessed only once when the application starts, solely for the purpose of managing object lifecycles.
With samber/do, we can implement health checks and shutdown functions for our objects:
type TestRepository struct {
client DatabaseClient
}
func (t *TestRepository) Shutdown() error {
return t.client.Close()
}
func (t *TestRepository) HealthCheck() error {
return t.client.Ping()
}One of the key benefits of do is that it determines the order in which objects are instantiated and ensures that
shutdown and health check functions run in the correct sequence.
For example, if we shut down an a repository before shutting the HTTP server, ongoing requests may fail. do ensures
that shutdown operations happen in reverse order of instantiation, minimizing such issues and improving liveness,
readiness, and graceful shutdown handling.
Performance
Use Automaxprocs for GOMAXPROCS
The Go scheduler is designed to utilize as many threads as the number of CPU cores available on the host machine. In a Kubernetes environment, where multiple applications share the same node, the total number of cores can be significantly high. By default, a Go application may attempt to utilize all available cores, potentially leading to resource contention.
To optimize CPU utilization and ensure fair resource allocation, we can use
automaxprocs. This package automatically adjusts GOMAXPROCS to match the
CPU limits specified in the application's Kubernetes deployment, ensuring that the Go runtime only schedules as many
threads as permitted.
By integrating automaxprocs, we can achieve:
- Better resource efficiency by preventing excessive CPU usage.
- Improved stability in multi-tenant Kubernetes clusters.
- Automatic scaling based on defined resource constraints without manual configuration.
Implementation
To enable automaxprocs, simply import the package in your application:
import _ "go.uber.org/automaxprocs"This ensures that GOMAXPROCS is dynamically adjusted at startup, aligning with the CPU limits defined in the
Kubernetes YAML configuration.
Optimizing Struct Memory Layout
The order of fields in a struct can significantly impact memory usage due to memory alignment.
Consider the following example:
type testStruct struct {
testBool1 bool // 1 byte
testFloat1 float64 // 8 bytes
testBool2 bool // 1 byte
testFloat2 float64 // 8 bytes
}At first glance, this struct might seem to occupy 18 bytes, but it actually takes up 32 bytes:
func main() {
a := testStruct{}
fmt.Println(unsafe.Sizeof(a)) // 32 bytes
}This discrepancy occurs due to how memory alignment works on a 64-bit architecture. For more details, refer to this article.
To minimize memory overhead, we can reorder the fields to align them more efficiently:
type testStruct struct {
testFloat1 float64 // 8 bytes
testFloat2 float64 // 8 bytes
testBool1 bool // 1 byte
testBool2 bool // 1 byte
}
func main() {
a := testStruct{}
fmt.Println(unsafe.Sizeof(a)) // 24 bytes
}You don't have to manually reorder fields every time. Tools like
fieldalignment can automatically optimize
the memory layout of your structs.
To apply the optimization, simply run:
fieldalignment -fix ./...This tool helps improve memory efficiency in your Go code by rearranging struct fields based on memory padding rules.
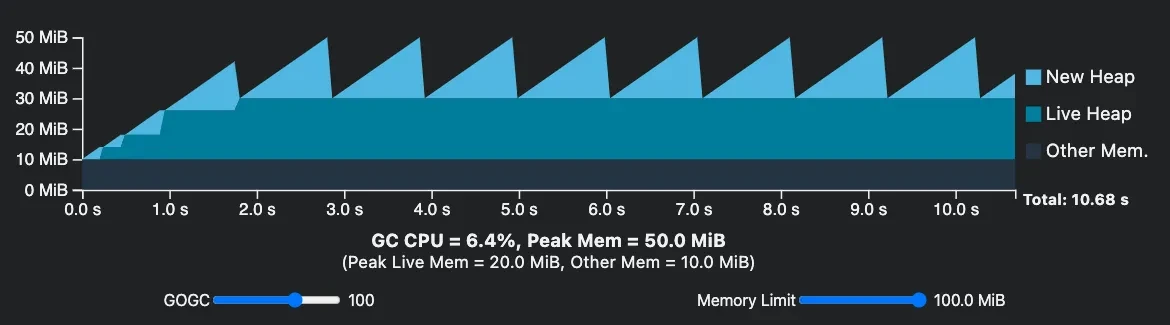
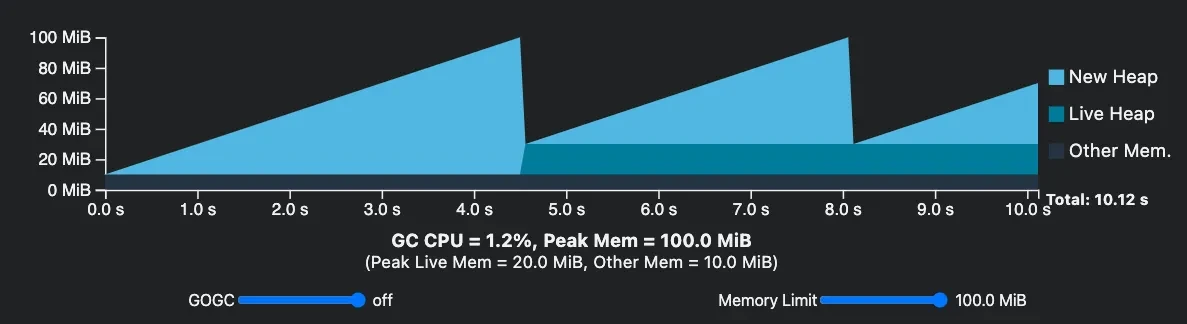
Use GOMEMLIMIT Instead of GOGC
Before Go 1.19, the only option to configure the GC cycle was GOGC (runtime/debug.SetGCPercent). However, this could
lead to scenarios where memory limits were exceeded. With Go 1.19, the introduction of GOMEMLIMIT provides a new
environment variable that allows users to limit the amount of memory a Go process can use. This feature offers better
control over the memory usage of Go applications, preventing excessive memory consumption and potential performance
issues or crashes. By setting the GOMEMLIMIT variable, users can ensure that their Go programs run smoothly and
efficiently without causing undue strain on the system. GOMEMLIMIT does not replace GOGC but works in conjunction with
it. It is also possible to disable the GOGC percent configuration and use only GOMEMLIMIT to trigger Garbage Collection.
While there is a significant decrease in the amount of garbage collection running, caution is advised. If the memory
limits of your application are not well understood, do not set GOGC=off.
Implementation
To set GOMEMLIMIT, use the following environment variable configuration:
export GOMEMLIMIT=512MiBThis sets the memory limit to 512 MiB. Adjust the value based on your application's requirements.
To disable GOGC and rely solely on GOMEMLIMIT, set GOGC to off:
export GOGC=offHowever, be cautious when doing this, as it may lead to unexpected behavior if the memory limits are not well understood.
Use Goroutine Pool by Using ants
Creating a new goroutine for each task can be expensive, especially in high-concurrency scenarios. Each goroutine consumes memory (typically around 2 KB), and spawning too many goroutines can lead to excessive context switching and memory usage.
ants is a high-performance goroutine pool implementation that reuses goroutines to reduce the overhead of goroutine creation and destruction. It manages a pool of worker goroutines that can be reused across multiple tasks, significantly reducing memory usage and improving performance under high concurrency.
Example Usage:
package main
import (
"fmt"
"sync"
"time"
"github.com/panjf2000/ants/v2"
)
func main() {
defer ants.Release()
var wg sync.WaitGroup
// Create a pool with a capacity of 10000 goroutines
p, _ := ants.NewPool(10000)
defer p.Release()
for i := 0; i < 100000; i++ {
wg.Add(1)
// Submit tasks to the pool
_ = p.Submit(func() {
time.Sleep(10 * time.Millisecond)
wg.Done()
})
}
wg.Wait()
fmt.Printf("running goroutines: %d\n", p.Running())
}As shown in the benchmark, using ants goroutine pool reduces memory usage by over 90% and improves execution time by more than 60% when handling a large number of short-lived tasks.
Avoid Large Value Copies by Using Pointers
When working with large structs or slices, passing them by value creates a complete copy of the data, which can significantly impact performance due to increased memory allocation and CPU usage. Using pointers for large data structures helps avoid unnecessary copying.
| Bad | Good |
|---|---|
| |
Benchmark Results:
func BenchmarkByValue(b *testing.B) {
data := LargeStruct{}
b.ResetTimer()
for i := 0; i < b.N; i++ {
ProcessByValue(data)
}
}
func BenchmarkByPointer(b *testing.B) {
data := LargeStruct{}
b.ResetTimer()
for i := 0; i < b.N; i++ {
ProcessByPointer(&data)
}
}| Benchmark | Operations | ns/op |
|---|---|---|
| BenchmarkByValue | 2044063 | 572.9 ns/op |
| BenchmarkByPointer | 3079296 | 390.7 ns/op |
As the benchmark shows, passing large structs by pointer can be faster.
When to use pointers:
- For large structs (generally over 64 bytes)
- When you need to modify the original data
- For slices with large underlying arrays
- For frequently called functions that handle substantial data
Note: For small structs (under 64 bytes), passing by value can sometimes be more efficient due to cache locality and reduced indirection.
Use Buffered Channels for Better Performance
When working with channels in Go, using unbuffered channels can lead to unnecessary blocking and context switching. Buffered channels reduce synchronization overhead by allowing a specified number of elements to be sent without blocking.
| Unbuffered | Buffered |
|---|---|
| |
Benchmark Results:
func BenchmarkUnbufferedChannel(b *testing.B) {
for i := 0; i < b.N; i++ {
ch := make(chan int)
go func() {
for i := 0; i < 100; i++ {
ch <- i
}
close(ch)
}()
for range ch {
// Do nothing, just receive
}
}
}
func BenchmarkBufferedChannel(b *testing.B) {
for i := 0; i < b.N; i++ {
ch := make(chan int, 100)
go func() {
for i := 0; i < 100; i++ {
ch <- i
}
close(ch)
}()
for range ch {
// Do nothing, just receive
}
}
}| Benchmark | Operations | ns/op |
|---|---|---|
| BenchmarkUnbufferedChannel | 85735 | 13745 ns/op |
| BenchmarkBufferedChannel | 281250 | 4132 ns/op |
As shown in the benchmark, buffered channels can be approximately 3 times faster than unbuffered channels for this specific workload. However, the optimal buffer size depends on your specific use case:
- Too small: May not provide enough benefits over unbuffered channels
- Too large: Can waste memory and mask potential deadlocks
Guidelines for buffer sizing:
- For predictable producer-consumer scenarios, set the buffer size to accommodate the expected burst of messages
- For bursty workloads, buffer size should match the expected maximum burst size
- For throttling, set the buffer size to the maximum concurrent operations you want to allow
Remember that while buffered channels improve performance, they can also hide synchronization issues that would be immediately apparent with unbuffered channels.
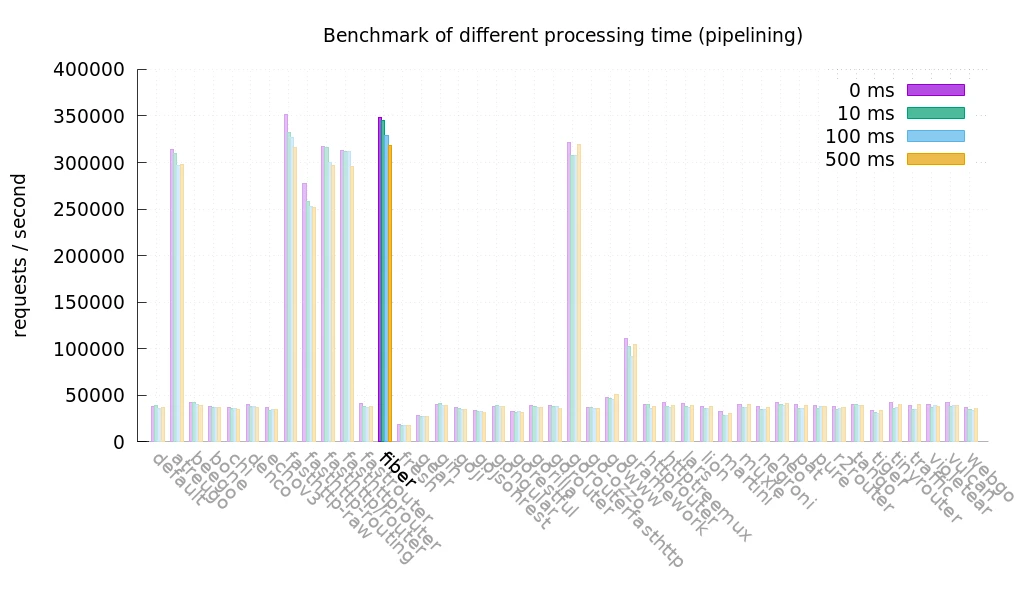
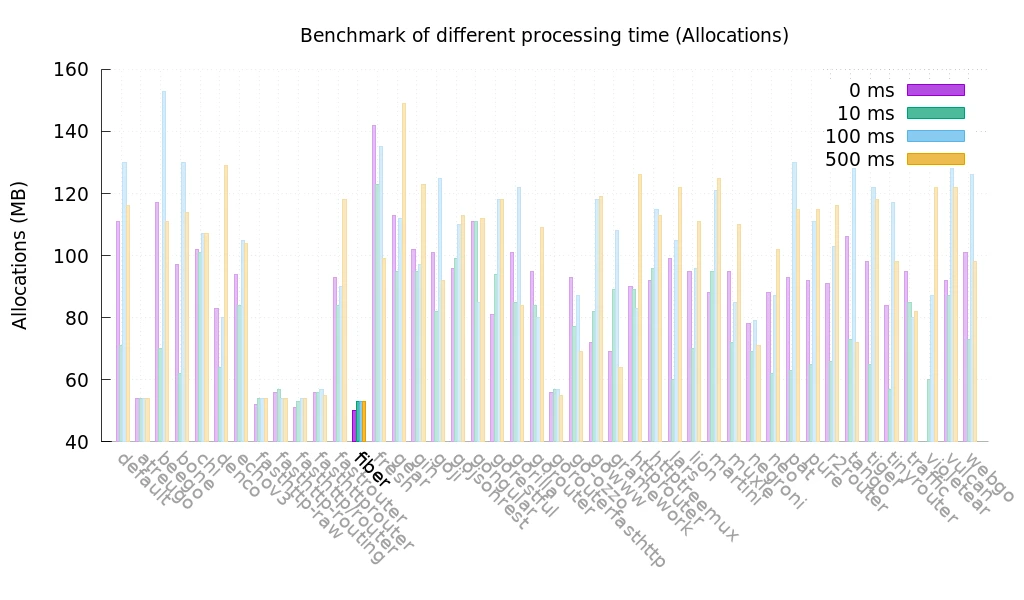
Use fiber for Web Framework
fiber is a lightweight and high-performance web framework built on fasthttp, the fastest HTTP engine in Go. It is optimized for speed and low memory consumption, making it ideal for building fast APIs and microservices. Compared to net/http, fiber significantly reduces request processing overhead and offers built-in support for middleware, WebSockets, and routing optimizations.
Use Concurrent Swiss Map for High-Performance Thread-Safe Maps
When working with maps in concurrent environments, the standard approach is to use either a map with a mutex/RWMutex or
sync.Map. However, both solutions have performance limitations in high-concurrency scenarios.
Concurrent Swiss Map is a high-performance, thread-safe generic concurrent hash map implementation that delivers exceptional performance in concurrent access scenarios.
Key Features:
- Thread-safe with minimal lock contention through map sharding
- High-performance for both read and write operations
- Lower memory usage compared to other concurrent map implementations
- Generic support (Go 1.18+)
- Simple API similar to built-in maps
Architecture:
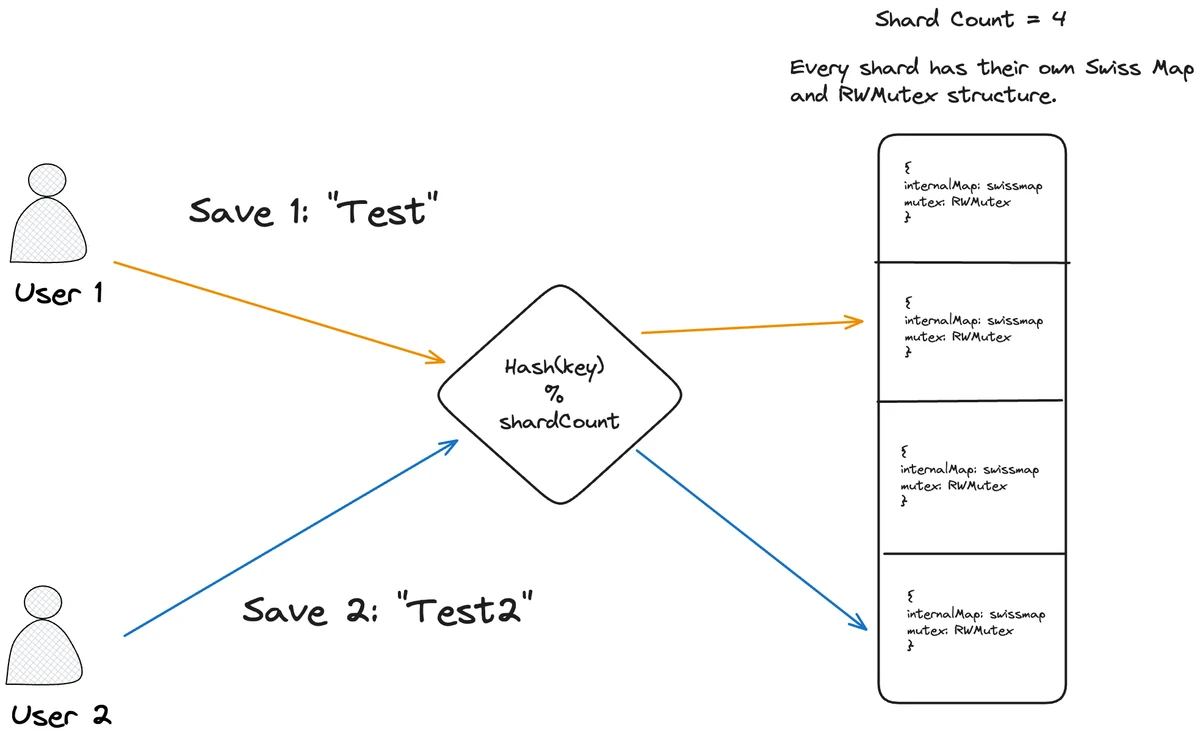
The diagram illustrates how the Concurrent Swiss Map divides a single map into multiple shards, with each shard protected by its own mutex. This approach significantly reduces lock contention in multi-threaded applications.
Example Usage:
package main
import (
"hash/fnv"
csmap "github.com/mhmtszr/concurrent-swiss-map"
)
func main() {
myMap := csmap.New[string, int](
// Set the number of map shards (default is 32)
csmap.WithShardCount[string, int](32),
// Optional custom hasher (defaults to built-in maphash)
csmap.WithCustomHasher[string, int](func(key string) uint64 {
hash := fnv.New64a()
hash.Write([]byte(key))
return hash.Sum64()
}),
// Set initial capacity
csmap.WithSize[string, int](1000),
)
// Basic operations
myMap.Store("key", 42) // Store a value
value, exists := myMap.Load("key") // Load a value
count := myMap.Count() // Get item count
myMap.Delete("key") // Delete a key
// Iterate over all entries
myMap.Range(func(key string, value int) (stop bool) {
// Process each key-value pair
return false // Return true to stop iteration
})
}Benchmark Results:
Benchmark tests show that Concurrent Swiss Map outperforms other map implementations in high-concurrency scenarios and uses less memory in all tested scenarios:
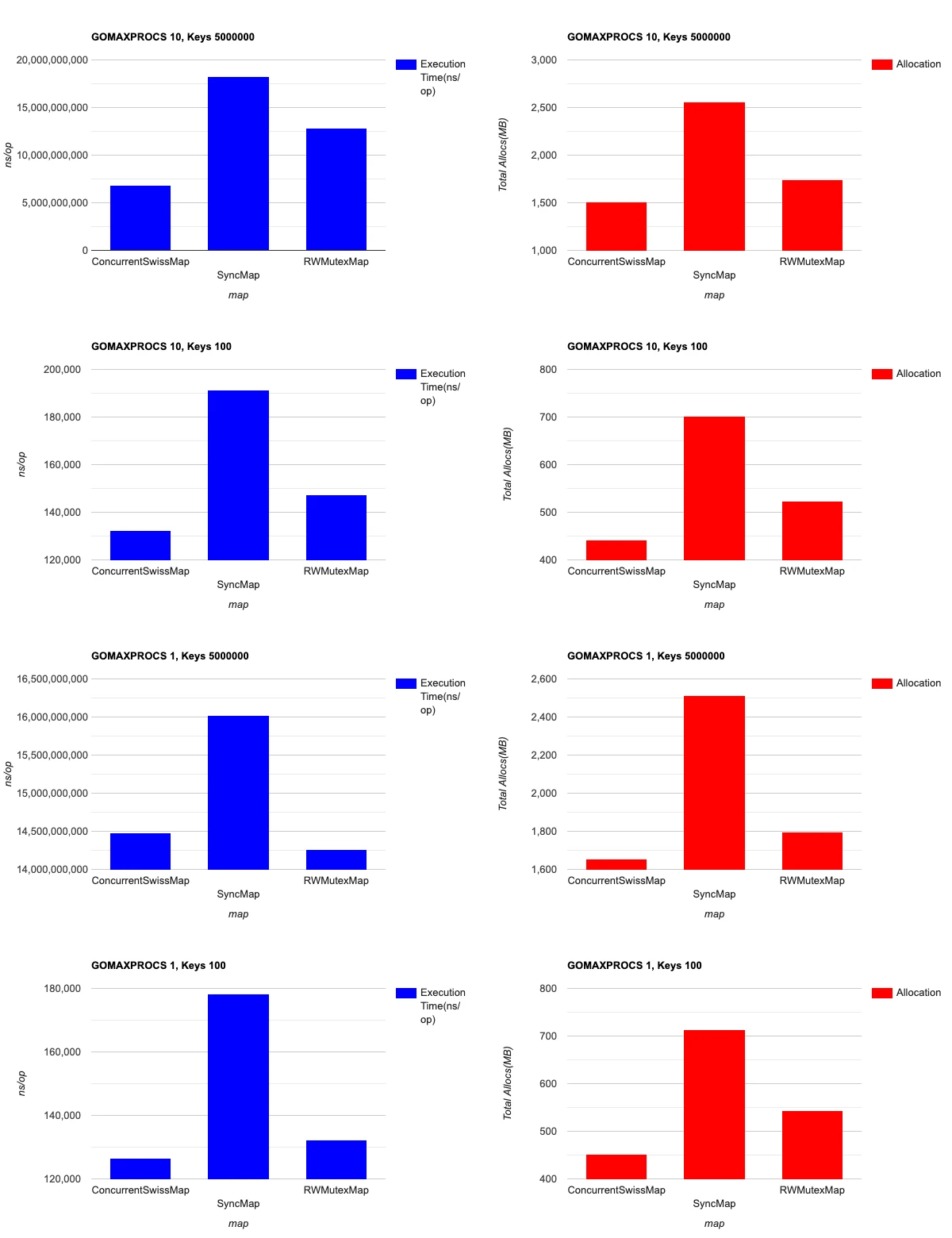
Key findings:
- Memory usage of the Concurrent Swiss Map is better than other map implementations in all test scenarios
- In highly concurrent systems, Concurrent Swiss Map is significantly faster than alternatives
- In systems with few concurrent operations, it offers performance similar to RWMutexMap
The implementation uses a sharding technique that divides the map into multiple segments, each with its own lock, dramatically reducing contention when multiple goroutines access different parts of the map simultaneously.
Use unsafe Package to String Byte Conversion without Copying
In Go, converting between string and []byte typically involves a memory copy. However, since both types internally
use
StringHeader and SliceHeader, we can use the unsafe package to avoid extra allocations:
func StringToBytes(s string) []byte {
return unsafe.Slice(unsafe.StringData(s), len(s))
}
func BytesToString(b []byte) string {
return unsafe.String(unsafe.SliceData(b), len(b))
}Libraries like fasthttp and fiber leverage this approach for better performance. Note: Avoid this if the underlying
data may change, as it could lead to unexpected behavior.
Note. If your byte or string values are likely to change later, do not use this feature.
Use bytedance/sonic instead of encoding/json
Go's standard encoding/json is known for being slow due to excessive
reflection. bytedance/sonic is a drop-in replacement that offers significant
performance
improvements.
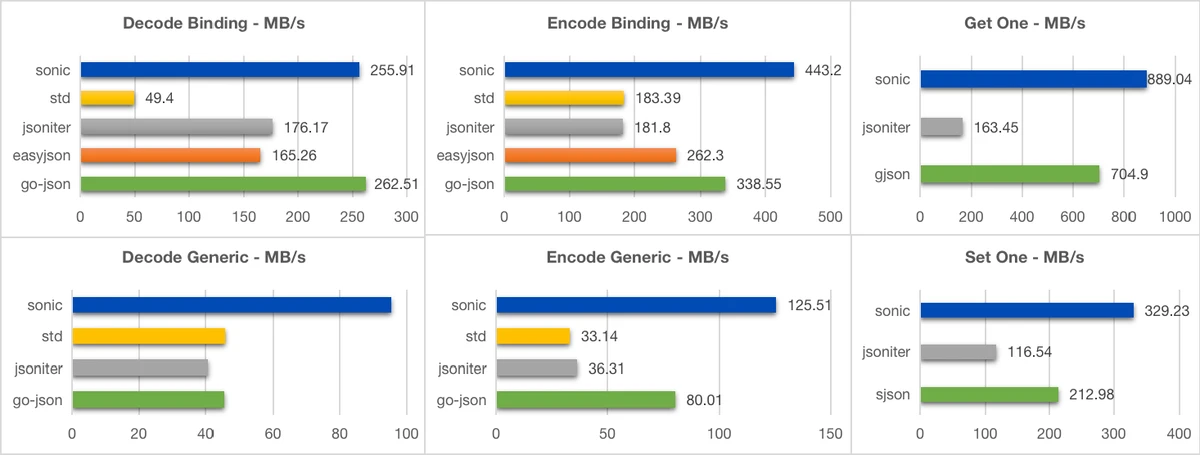
Small (400B, 11 keys, 3 layers)
Large (635KB, 10000+ key, 6 layers)
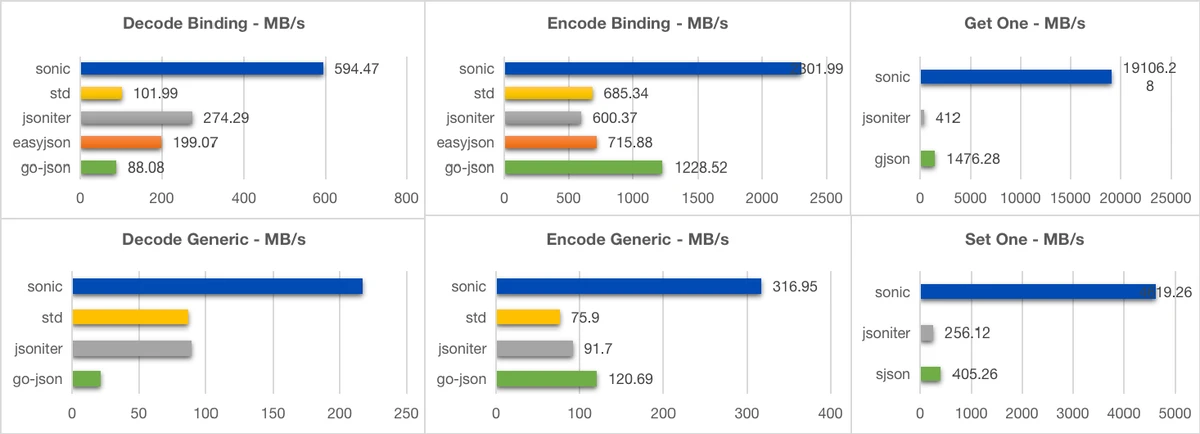
Benchmarks show that bytedance/sonic provides faster serialization and deserialization with lower memory overhead.
Example Usage:
import "github.com/bytedance/sonic"
sonic.Marshal(&data)
sonic.Unmarshal(input, &data)Use sync.Pool to reduce heap allocations
Frequent object allocation and garbage collection impact performance. sync.Pool helps by reusing objects instead of creating new instances each time.
type Person struct {
Name string
}
var pool = sync.Pool{
New: func() any {
fmt.Println("Creating a new instance")
return &Person{}
},
}
func main() {
person := pool.Get().(*Person)
fmt.Println("Get object from sync.Pool for the first time:", person)
person.Name = "Mehmet"
fmt.Println("Put the object back in the pool")
pool.Put(person)
fmt.Println("Get object from pool again:", pool.Get().(*Person))
fmt.Println("Get object from pool again (new one will be created):", pool.Get().(*Person))
}
//Creating a new instance
//Get object from sync.Pool for the first time: &{}
//Put the object back in the pool
//Get object from pool again: &{Mehmet}
//Creating a new instance
//Get object from pool again (new one will be created): &{}Using sync.Pool, I helped resolve a memory leak in New Relic Go Agent. Instead of creating a new gzip writer for every request, I introduced a pool to reuse instances, reducing CPU usage by ~ 40% and memory usage by ~22%.
Prefer strconv over fmt
When converting primitives to/from strings, strconv is faster than fmt.
| Bad | Good |
|---|---|
| |
| |
Prefer specifying capacity for slices and maps
When creating slices and maps, specifying the capacity can improve performance by reducing the number of reallocations.
| Bad | Good |
|---|---|
| |
| |
Do not return a pointer from a function
Returning a pointer from a function may cause the variable to escape to the heap(depending on the escape analysis result), increasing CPU usage and garbage collection pressure. Instead, return the value directly to avoid unnecessary heap allocations.
| Bad | Good |
|---|---|
| |
By returning the value directly, we can reduce heap allocations and improve performance.
type Reader interface {
Read(p []byte) (n int, err error)
}That's why the built-in Go Reader interface's Read function does not return a []byte; instead, it takes the buffer as a parameter to avoid heap allocation.
Avoid repeated string-to-byte conversions
Do not create byte slices from a fixed string repeatedly. Instead, perform the conversion once and capture the result.
| Bad | Good |
|---|---|
| |
| |
Patterns
Functional Options
Functional options is a pattern in which you declare an opaque Option type
that records information in some internal struct. You accept a variadic number
of these options and act upon the full information recorded by the options on
the internal struct.
Use this pattern for optional arguments in constructors and other public APIs that you foresee needing to expand, especially if you already have three or more arguments on those functions.
| Bad | Good |
|---|---|
| |
The cache and logger parameters must always be provided, even if the user wants to use the default. | Options are provided only if needed. |
Our suggested way of implementing this pattern is with an Option interface
that holds an unexported method, recording options on an unexported options
struct.
type options struct {
cache bool
logger *zap.Logger
}
type Option interface {
apply(*options)
}
type cacheOption bool
func (c cacheOption) apply(opts *options) {
opts.cache = bool(c)
}
func WithCache(c bool) Option {
return cacheOption(c)
}
type loggerOption struct {
Log *zap.Logger
}
func (l loggerOption) apply(opts *options) {
opts.logger = l.Log
}
func WithLogger(log *zap.Logger) Option {
return loggerOption{Log: log}
}
// Open creates a connection.
func Open(
addr string,
opts ...Option,
) (*Connection, error) {
options := options{
cache: defaultCache,
logger: zap.NewNop(),
}
for _, o := range opts {
o.apply(&options)
}
// ...
}Note that there's a method of implementing this pattern with closures but we
believe that the pattern above provides more flexibility for authors and is
easier to debug and test for users. In particular, it allows options to be
compared against each other in tests and mocks, versus closures where this is
impossible. Further, it lets options implement other interfaces, including
fmt.Stringer which allows for user-readable string representations of the
options.
See also,
Testing
Unit Testing for Usecases
It is essential to write unit tests for our usecase packages, as they contain the business logic that is accessed
externally. Any interaction with third-party services, such as databases or external APIs, should be abstracted behind
interfaces to facilitate mocking.
Using Mockery for Mock Generation
For generating mocks, we can use Mockery. Below is a recommended .mockery.yml
configuration:
with-expecter: true
mockname: "{{.InterfaceName}}"
outpkg: "mocks"
filename: "{{.InterfaceName | snakecase}}.go"
packages:
<your-app-name>:
config:
dir: "mocks"
recursive: trueMockery allows us to generate mock implementations from interfaces, making it easier to write isolated unit tests. However, we should not create interfaces solely for the purpose of mocking—interfaces should only be introduced when they provide clear benefits, such as enabling testability or supporting multiple implementations. Excessive use of interfaces can lead to unnecessary complexity and performance overhead, which we will discuss further in the Performance section.
Using Table-Driven Tests
When testing a function with different inputs and expected outputs, we should use table-driven tests to ensure better coverage and maintainability. This approach allows us to define multiple test cases in a structured manner.
Example:
func TestSum(t *testing.T) {
tests := []struct {
name string
a, b int
expected int
}{
{"both positive", 3, 5, 8},
{"positive and negative", 7, -2, 5},
{"both negative", -4, -6, -10},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
result := Sum(tt.a, tt.b)
if result != tt.expected {
t.Errorf("expected %d, got %d", tt.expected, result)
}
})
}
}Running Tests with the Race Detector
To catch race conditions early, all tests should be run with the --race flag enabled:
go test ./... -raceThis helps detect potential data races, ensuring our code is safe for concurrent execution.
Parallel Tests
Parallel tests, like some specialized loops (for example, those that spawn goroutines or capture references as part of the loop body), must take care to explicitly assign loop variables within the loop's scope to ensure that they hold the expected values.
tests := []struct{
give string
// ...
}{
// ...
}
for _, tt := range tests {
tt := tt // for t.Parallel
t.Run(tt.give, func(t *testing.T) {
t.Parallel()
// ...
})
}In the example above, we must declare a tt variable scoped to the loop
iteration because of the use of t.Parallel() below.
If we do not do that, most or all tests will receive an unexpected value for
tt, or a value that changes as they're running.
Detecting Goroutine Leaks with goleak
Goroutine leaks are a common source of memory leaks in Go applications. They occur when goroutines are created but never terminated, often due to blocked channels or improperly managed resources. These leaks can accumulate over time, eventually leading to memory exhaustion and application failure.
goleak is a library by Uber that helps detect goroutine leaks in tests. By checking for any non-terminated goroutines at the end of a test, it ensures your code properly cleans up all concurrent operations.
Basic Usage:
import (
"testing"
"go.uber.org/goleak"
)
func TestMain(m *testing.M) {
// Set up goleak for the entire test suite
goleak.VerifyTestMain(m)
}
// For individual tests
func TestFunction(t *testing.T) {
defer goleak.VerifyNone(t)
// Your test code here
}Example with Custom Options:
func TestWithOptions(t *testing.T) {
// Ignore goroutines created by the standard library's HTTP client
opts := []goleak.Option{
goleak.IgnoreTopFunction("internal/poll.runtime_pollWait"),
goleak.IgnoreTopFunction("net/http.(*Transport).dialConn"),
}
defer goleak.VerifyNone(t, opts...)
// Test code that makes HTTP requests
http.Get("https://example.com")
}Handling Goroutine Leaks:
When a leak is detected, goleak provides information about the leaking goroutines, including their stack traces. This helps identify the source of the leak:
Found 1 unexpected goroutines:
#1: created by example/service.StartWorker
/path/to/your/code/service.go:42 +0x123
... (stack trace continues)To fix leaks, ensure all goroutines have proper termination conditions:
- Add context cancellation
- Implement shutdown mechanisms
- Ensure channels are properly closed
By incorporating goleak into your test suite, you can catch and fix goroutine leaks early in the development process, preventing them from causing issues in production.
Fuzz Testing
Fuzz testing (or fuzzing) is a technique that provides random or semi-random inputs to your code to discover edge cases and bugs that might not be caught by regular testing. Go has native support for fuzz testing since Go 1.18, making it easy to implement robust fuzz tests.
Unlike traditional unit tests with predefined inputs and expected outputs, fuzz tests use the Go fuzzing engine to generate inputs automatically, helping uncover issues like panics, crashes, and unexpected behaviors.
Basic Fuzz Test Example:
package example
import (
"testing"
"unicode/utf8"
)
// Function we want to test
func Reverse(s string) string {
b := []byte(s)
for i, j := 0, len(b)-1; i < len(b)/2; i, j = i+1, j-1 {
b[i], b[j] = b[j], b[i]
}
return string(b)
}
// Regular test with predefined cases
func TestReverse(t *testing.T) {
testcases := []struct {
in, want string
}{
{"Hello, world", "dlrow ,olleH"},
{"", ""},
{"!12345", "54321!"},
}
for _, tc := range testcases {
got := Reverse(tc.in)
if got != tc.want {
t.Errorf("Reverse(%q) = %q, want %q", tc.in, got, tc.want)
}
}
}
// Fuzz test for the same function
func FuzzReverse(f *testing.F) {
// Provide seed corpus
testcases := []string{"Hello, world", "", "!12345"}
for _, tc := range testcases {
f.Add(tc) // Add seed corpus
}
// Fuzz test function
f.Fuzz(func(t *testing.T, orig string) {
// Skip invalid UTF-8 strings
if !utf8.ValidString(orig) {
return
}
rev := Reverse(orig)
doubleRev := Reverse(rev)
// Property: reversing twice should return original string
if orig != doubleRev {
t.Errorf("Reverse(Reverse(%q)) = %q, want %q", orig, doubleRev, orig)
}
// Check if the reversed string has the same length
if len(orig) != len(rev) {
t.Errorf("len(%q) = %d, len(%q) = %d", orig, len(orig), rev, len(rev))
}
})
}Running Fuzz Tests:
# Run the fuzz test
go test -fuzz=FuzzReverse -fuzztime=30s
# When a failure is found, a test case is added to the testdata directory
# You can run the specific failed case using:
go test -run=FuzzReverse/testdata/fuzz/FuzzReverse/123456Best Practices for Fuzz Testing:
-
Define Properties: Instead of checking for specific outputs, verify properties that should always hold true ( e.g., reversing a string twice should return the original string).
-
Provide Seed Corpus: Include known test cases to help the fuzzer start with meaningful inputs.
-
Handle Invalid Inputs: Add checks to skip or properly handle invalid inputs that might be generated by the fuzzer.
-
Use Constraints: If needed, constrain input generation using custom functions or by handling specific edge cases.
-
Fix All Discovered Issues: When a fuzz test finds a bug, add a regression test case to your regular tests.
Fuzz testing is particularly valuable for:
- Parsing and encoding/decoding functions
- Data validation and sanitization
- Complex algorithms with many edge cases
- Security-critical code that processes untrusted inputs
By adding fuzz testing to your Go projects, you can discover bugs that traditional testing methods might miss, leading to more robust and resilient code.
Error Handling
The error message must be in all lowercase letters. This is consistent with the Go standard library and helps maintain a uniform style across the codebase.
Error Types
There are few options for declaring errors. Consider the following before picking the option best suited for your use case.
- Does the caller need to match the error so that they can handle it?
If yes, we must support the
errors.Isorerrors.Asfunctions by declaring a top-level error variable or a custom type. - Is the error message a static string,
or is it a dynamic string that requires contextual information?
For the former, we can use
errors.New, but for the latter we must usefmt.Errorfor a custom error type. - Are we propagating a new error returned by a downstream function? If so, see the section on error wrapping.
| Error matching? | Error Message | Guidance |
|---|---|---|
| No | static | errors.New |
| No | dynamic | fmt.Errorf |
| Yes | static | top-level var with errors.New |
| Yes | dynamic | custom error type |
For example,
use errors.New for an error with a static string.
Export this error as a variable to support matching it with errors.Is
if the caller needs to match and handle this error.
| No error matching | Error matching |
|---|---|
| |
For an error with a dynamic string,
use fmt.Errorf if the caller does not need to match it,
and a custom error if the caller does need to match it.
| No error matching | Error matching |
|---|---|
| |
Note that if you export error variables or types from a package, they will become part of the public API of the package.
Error Wrapping
There are three main options for propagating errors if a call fails:
- return the original error as-is
- add context with
fmt.Errorfand the%wverb
Return the original error as-is if there is no additional context to add. This maintains the original error type and message. This is well suited for cases when the underlying error message has sufficient information to track down where it came from.
Otherwise, add context to the error message where possible so that instead of a vague error such as "connection refused", you get more useful errors such as "call service foo: connection refused".
Use fmt.Errorf and %w to add context to your errors,
- Use
%wif the caller should have access to the underlying error. This is a good default for most wrapped errors, but be aware that callers may begin to rely on this behavior. So for cases where the wrapped error is a knownvaror type, document and test it as part of your function's contract.
When adding context to returned errors, keep the context succinct by avoiding phrases like "failed to", which state the obvious and pile up as the error percolates up through the stack:
| Bad | Good |
|---|---|
| |
| |
However once the error is sent to another system, it should be clear the
message is an error (e.g. an err tag or "Failed" prefix in logs).
See also Don't just check errors, handle them gracefully.
Error Naming
For error values stored as global variables,
use the prefix Err or err depending on whether they're exported.
This guidance supersedes the Prefix Unexported Globals with _.
var (
// The following two errors are exported
// so that users of this package can match them
// with errors.Is.
ErrBrokenLink = errors.New("link is broken")
ErrCouldNotOpen = errors.New("could not open")
// This error is not exported because
// we don't want to make it part of our public API.
// We may still use it inside the package
// with errors.Is.
errNotFound = errors.New("not found")
)For custom error types, use the suffix Error instead.
// Similarly, this error is exported
// so that users of this package can match it
// with errors.As.
type NotFoundError struct {
File string
}
func (e *NotFoundError) Error() string {
return fmt.Sprintf("file %q not found", e.File)
}
// And this error is not exported because
// we don't want to make it part of the public API.
// We can still use it inside the package
// with errors.As.
type resolveError struct {
Path string
}
func (e *resolveError) Error() string {
return fmt.Sprintf("resolve %q", e.Path)
}Handle Errors Once
When a caller receives an error from a callee, it can handle it in a variety of different ways depending on what it knows about the error.
These include, but not are limited to:
- if the callee contract defines specific errors,
matching the error with
errors.Isorerrors.Asand handling the branches differently - if the error is recoverable, logging the error and degrading gracefully
- if the error represents a domain-specific failure condition, returning a well-defined error
- returning the error, either wrapped or verbatim
Regardless of how the caller handles the error, it should typically handle each error only once. The caller should not, for example, log the error and then return it, because its callers may handle the error as well.
For example, consider the following cases:
| Description | Code |
|---|---|
Bad: Log the error and return it Callers further up the stack will likely take a similar action with the error. Doing so causing a lot of noise in the application logs for little value. | |
Good: Wrap the error and return it Callers further up the stack will handle the error.
Use of | |
Good: Log the error and degrade gracefully If the operation isn't strictly necessary, we can provide a degraded but unbroken experience by recovering from it. | |
Good: Match the error and degrade gracefully If the callee defines a specific error in its contract, and the failure is recoverable, match on that error case and degrade gracefully. For all other cases, wrap the error and return it. Callers further up the stack will handle other errors. | |
Pre-Production Check
- ✅ Optimize CPU Utilization: If running in a containerized environment, integrate
automaxprocsto automatically adjustGOMAXPROCSbased on available CPU resources. - ✅ Health Checks: Ensure proper configuration of liveness and readiness probes in Kubernetes to improve service reliability and automated recovery.
- ✅ Graceful Shutdown: Implement a structured shutdown process to close resources in the correct order. See the container section for best practices.
- ✅ Static Code Analysis: Use
golangci-lintto detect and resolve code smells, potential bugs, and performance issues. - ✅ Logging, Monitoring & Alerts: Define structured logs, alerts, and metrics to track application health and performance.
- ✅ Escape Analysis: Review escape analysis reports to identify variables that unnecessarily escape to the heap, optimizing memory usage.
- ✅ Profiling & Leak Detection: Use
pproffor CPU and memory profiling to detect performance bottlenecks and memory leaks before deployment.